
In diesem Blogeintrag möchte ich meine persönlichen Erfahrungen über Captiva von OpenText zum Ausdruck bringen. Es kommt sehr häufig vor, dass weder Anwender, noch IT Spezialisten genau wissen was sich hinter diesem „Software-Werkzeug“ versteckt.
Ich habe auch schon öfter den Satz „Da wird ja bloß gescannt“ gehört und genau aus diesem Grunde ist es an der Zeit, das Mysterium Captiva Capture näher zu beleuchten. In einfachen Worten versuche ich in diesem Beitrag etwas über die Software selbst und über die täglichen Aufgaben und Problemstellungen zu erzählen. Vielleicht ist es dann nachvollziehbar, warum ich dieses Gebiet mit den damit verbundenen Tätigkeiten wahnsinnig spannend finde und dass sich dabei mehr verbirgt, als nur das Scannen.
Was ist Captiva Capture?
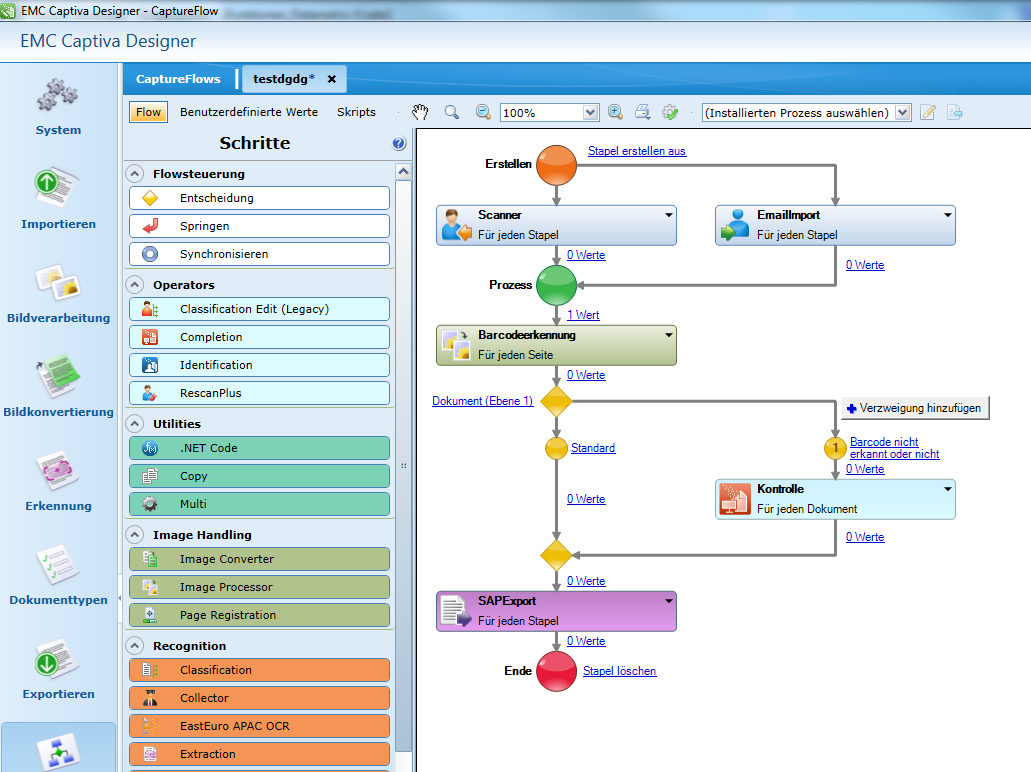
Captiva Capture von OpenText bietet im Bereich des Inputmanagements verschiedene Module, um Dokumente zu digitalisieren (scannen), importieren, verarbeiten und exportieren. Klassischerweise hat der User am Arbeitsplatz einen großen Stapel mit mehreren hunderten Rechnungen oder anderen beliebigen Formularen liegen und möchte diese entsprechend verarbeiten. Sicherlich kann sich jeder vorstellen, dass es nicht effizient ist, jedes Dokument einzeln einzuscannen und zu bearbeiten.
Genau hier schafft Captiva Capture direkte Abhilfe: Der Anwender packt einfach einen ganzen Stapel bestehend aus sämtlichen Dokumenten in den Scanner und braucht sich über das Auslesen von Kundennummern, Versicherungsnummern, Rechnungsbeträgen oder anderen wichtigen Inhalten keine Sorgen mehr zu machen. Alles geschieht automatisch!
Damit ist also das Scannen wirklich einer der kleinsten Teile in der Captiva Welt. Die Entwicklung der entsprechenden Prozesse für das Teilen der verschiedenen Dokumente nach Anbietern und das Auslesen von relevanten Inhalten ist der deutlich größere Faktor. Genau hier komme ich ins Spiel. Meine Aufgabe als Entwickler ist es dafür zu sorgen, dass der Anwender sich um möglichst wenig selbst kümmern muss.
Captiva stellt als Entwicklerwerkzeug eine Reihe von Funktionen und Modulen zur Verfügung, die eine flexible Prozessentwicklung möglich machen und nahezu sämtliche Anforderungen im Bereich des Inputmanagements abbilden. Neben dem Scannen können auch E-Mails und Dateien von einem Dateipfad als Quelle für den Import genutzt werden.
Was genau macht nun Captiva, welche Aufgaben habe ich dabei als Entwickler und was hat letzten Endes der Anwender noch zu tun? Dazu mehr in folgendem einfachen Praxisszenario.
Ausgangsbeispiel:
Ein Versicherungsunternehmen erhält täglich mehrere tausend Anschreiben von Krankenhäusern, die entsprechend Patienten behandelt haben. Dabei können die Rechnungen unterschiedlich aufgebaut sein. Nachdem die Dokumente im System gelandet sind sollen sie nach SAP exportiert und archiviert werden.
Was hat der Anwender zu tun?
Die Mitarbeiter des Versicherungsunternehmens gliedern sich bei diesem Prozess in zwei Aufgabenbereiche: Scannen und Kontrolle.
Die Scan-Mitarbeiter bereiten die Rechnungen vor, in dem sie sämtliche Dokumente von allen Kreditoren in einem Stapel zusammenfassen und einscannen. Konnte keine Rechnungsnummer und z. Bsp. kein Geburtsdatum des Patienten automatisiert ausgelesen werden (schlechte Qualität oder weil die Daten auf dem Dokument fehlen), landet die Rechnung bei einem Mitarbeiter zur Kontrolle. Dieser trägt die entsprechenden Daten manuell nach oder setzt ein Veto ein.
Was sollte der Entwickler beachten?
Mit Hilfe von Captiva und den entsprechenden Modulen sorge ich zunächst dafür, dass die E-Mails importiert werden. Dabei müssen auch diverse Sicherheitsrichtlinien eingebaut werden, damit kein „Unfug“ in das System gelangt.
Anschließend werden sämtliche Dokumente von Scan, E-Mail und Fax aufbereitet und auf Qualität geprüft. Es kommt nicht selten vor, dass viele Daten auf den Formularen nicht leserlich sind (schwarze Flecken, schlechte Druckqualität und verschwommene Inhalte). Hier ist es erforderlich mit diversen Filtern und „Regeln“ Abhilfe zu schaffen. Leere Seiten sollen gelöscht werden.
Im nächsten Schritt wird das Rechnungsdokument klassifiziert. Anhand verschiedener Kriterien (die dem System vorher beigebracht werden) erkennt Captiva, um welchen Kreditor es sich handelt. Dadurch ist genau bekannt, an welcher Stelle die Rechnungsnummer und das Geburtsdatum zu suchen ist.
Sollten keine gültigen Daten gefunden werden, bringe ich das Dokument zur Kontrolle an die entsprechende Anwendung und validiere die Eingabe des Users. Erst wenn die Pflichtfelder belegt und korrekt gefüllt sind bereite ich das Dokument samt Daten für den SAP-Export vor.
Parallel zum normalen „Rechnungslauf“ schreibe ich diverse Daten in eine intern geführte Statistik: Wie oft kommt es vor, dass ein Anwender kontrollieren muss? Warum musste kontrolliert werden (war keine Rechnungsnummer enthalten, oder war diese fehlerhaft)? Aus diesen Daten kann das Unternehmen Optimierungsprozesse erkennen und gemeinsam mit mir umsetzen.
Das war nur ein kleines Beispiel…
Dieses Beispiel zeigt jedoch, dass in vielen und vor allem größeren Unternehmen deutlich mehr als nur Scannen und Kontrollieren im Hintergrund läuft.
Im Hintergrund wird zunächst erstmal alles mit Hilfe von Captiva entwickelt, getestet und antrainiert. In der alltäglichen Praxis gilt es dabei noch viel größere Hürden zu bewältigen. Besonders wenn ein Unternehmen viele verschiedene Dokumentenarten und Prozesse intern für die Verarbeitung und Archivierung der Formulare nutzt. Dabei spielt es keine Rolle welche Anforderungen gestellt werden: Alles lässt sich aufbauen bzw. entwickeln. Egal ob Dokumente in das System rein oder raus sollen. Wie sie ausgelesen oder verarbeitet werden.
Kleine Herausforderungen im Alltag
Ein kleiner Überblick über typische „Probleme“ während der Entwicklung macht nochmal deutlich, dass selbst Kleinigkeiten manchmal zur Herausforderung werden.
- Bildqualitäten: Bei mehreren tausend verschiedenen Dokumenten sollte die Aufbereitung klug erstellt werden. Vieles was nicht leserlich ist, lässt sich verbessern.
- Ausfiltern von Dokumenten, die überhaupt nicht importiert werden sollen (Wenn beispielsweise der Anwender etwas Falsches gescannt hat.).
- Versicherungsnummer: Es sollte stets darauf geachtet werden, dass anstelle einer Versicherungsnummer keine andere Nummer bestehend aus gleicher Zahlenkombination ausgelesen wird. Beispielsweise wurde schon einmal eine Faxnummer anstelle der Versicherungsnummer ausgelesen.
- E-Mail Import: Es muss genau verifiziert werden, welche Dokumente und Inhalte gültig sind. Beispielsweise dürfen auch Bilder wie Twitter- oder Facebook-Logos in einer Signatur nicht verarbeitet bzw. als Dokument importiert werden.
- Faxe sind häufig seitenverdreht. Es muss sichergestellt werden, dass das Dokument korrekt angezeigt und archiviert wird. Auch ein entsprechendes Fehlerhandling für das Unternehmen sollte gewährleistet sein, um entsprechend zu reagieren.
- Was passiert wenn Dokumente nicht klassifiziert oder Barcodes nicht gelesen werden?
Wer sich noch nicht näher mit Captiva beschäftigt hat, für den erscheint das Verarbeiten der Daten als ganz selbstverständlich. Dennoch hoffe ich sehr, dass mein Blog dazu beiträgt aufzuzeigen, was die Software Lösung aus dem Hause OpenText bietet und welchen Herausforderungen man sich als Entwickler dabei stellt . Es macht einfach Spaß einen Prozess zu basteln, der im Idealfall alle Aufgaben nach dem Scan bzw. Import komplett übernimmt und kein manuelles Eingreifen der Anwender mehr nötig ist. Vom Erhalt der Rechnung bis hin zur Zahlung. Alles ganz automatisch – da bleibt bestimmt etwas mehr Zeit für einen guten Kaffee zwischendurch 🙂




0 Kommentare