
Microservice-Architekturen bestehen in der Regel aus mehreren autonomen, modularen und vernetzten Anwendungen. Eine solche Architektur stellt uns vor komplett neue Herausforderungen. Wie kann man alle Aufrufe der involvierten Dienste, welche Bestandteil einer einzelnen Anfrage sind, effektiv nachverfolgen? Wenn ein Client eine Operation aufruft, kann sich diese Anfrage auf verschiedene Microservices im Netzwerk verteilen; jeder Service mit seinem eigenen Kontext.
Wie stellt man zum Beispiel fest, dass Engpässe auftreten? Wie kann man die Dauer eines spezifischen Aufrufes innerhalb einer umfassenderen Operation, bestehend aus etlichen Microservices, bestimmen?
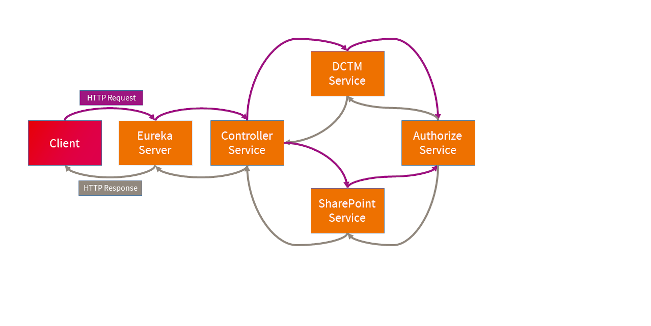
Traditionelle Werkzeuge wie Logging und Profiling können Daten nur in einem abgegrenzten Service Kontext sammeln. Microservices können aber on demand instanziiert und auch zerstört werden, wodurch das Auffinden geeigneter Logs nahezu unmöglich wird. Um ein Gesamtbild über Microservice-Grenzen hinweg zu erhalten, benötigen wir neue Ansätze.
Distributed Tracing
Genau diese Punkte adressiert das Distributed Tracing. Es handelt sich um eine Technologie/Konzept, welche Trace-Daten zwischen verschiedenen Aufrufen der Microservices mitliefert. Das System generiert beim ersten Aufruf eine Root Trace ID, um die übergeordnete Operation zu identifizieren. Jeder Aufruf eines Microservices erzeugt einen sogenannten Span mit einer eindeutigen Span ID. Bei verschachtelten Microservice-Aufrufen wird zusätzlich eine sogenannte Parent Span ID mit an die involvierten Microservices übergeben. Mit diesen drei IDs ist der Trace Server in der Lage Verschachtelungen und Abhängigkeiten der Microservices zu identifizieren und strukturiert in einem Web-UI darzustellen. Diese Tracing-Daten werden wahlweise flüchtig im Hauptspeicher oder persistent in einer Datenbank abgelegt. Über ein UI kann man dann einen Überblick über den zeitlichen Ablauf jedes einzelnen Aufrufs nachvollziehen. Abgeschlossene Traces werden asynchron zusammengeführt, um Overhead zu verringern. Wenn gewünscht, kann der Tracing Server auch in einem Docker Container betrieben werden.
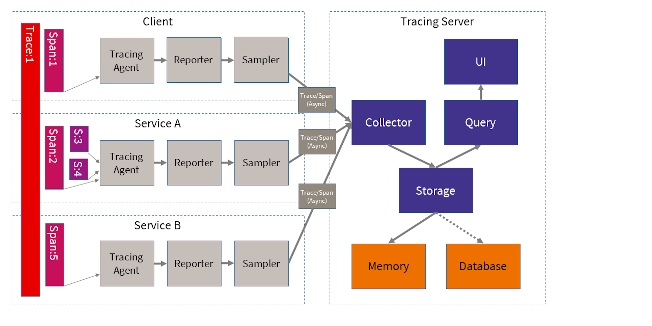
Ein Distributed Tracing lässt sich sehr einfach in ein System integrieren. Man muss einen Tracing Agent mit einem Reporter so konfigurieren, dass dieser auf den Tracing Server verweist. Bei sehr ressourcenintensiven Systemen kann man den Tracing Agent so konfigurieren, dass lediglich ein Auszug der Tracing-Daten weitergeleitet wird. Wie bereits oben erwähnt, wird durch Trace, Span und Parent Span ID der Fluss der Microservice-Aufrufe beschrieben. Ein Span ist im gewissen Sinne die kleinste Klammerung um eine Abfolge von Befehlen. Bei Bedarf können neue Sub Spans erzeugt werden (z.B. um Sub-Routinen im Tracing besonders kenntlich zu machen).
Spans können folgende, zusätzliche Informationen aufnehmen:
- Zeitstempel: als Abschluss eines Zwischenschrittes ohne einen weiteren Span anzulegen
- Anmerkungen: text-basierte Informationen, z.B. essentielle Informationen, die den Fluss beeinflussen, oder kritische Fehlermeldungen, die über die hierarchische Darstellung des Tracing Servers mehr Aufschluss geben
- Tags: Schlüssel-/Wert-Paare zur Klassifizierung
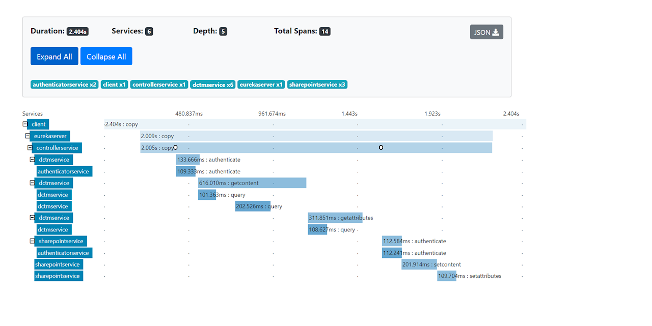
Für eine spezifischen Trace ID kann man im User Interface die Zeitschiene jedes Spans sehen. Jede Zeile stellt dabei einen Span dar, der durch einen Microservice generiert wurde. Man sieht jeweils, wann der Span begonnen wurde, wie lange er dauerte und wann er endete, die Aufrufhierarchie, sowie die Ereignisse (Zeitstempel) und Schlüssel-/Werte-Paare.
Go to market
Bekannte Distributed Tracing-Systeme sind u.a. Zipkin und Jaeger. Zipkin ist ursprünglich durch Twitter entwickelt worden und Jaeger durch Uber. Heute jedoch sind beides Open Source-Softwareprojekte.
Beide haben eine ähnliche Architektur:
- In Docker Containern lauffähig
- Anzeige von Timelines in der Web UI
- Anzeige von Traces und Spans
- Senden von Auszügen
- Speichern der Tracing-Daten in/im: Hauptspeicher, Cassandra, ElasticSearch, MySQL
- Unterstützung zahlreicher Sprachen durch Bereitstellung einer Client API: C++, C#, GO, Java, Python, Ruby, Node.js, Scala, PHP
In einer Spring Cloud-Anwendung lässt sich Zipkin relativ einfach, durch das Verwenden von Spring Cloud Sleuth und das Hinzufügen gezielter Konfigurationen und Java Annotations, integrieren. Spring Cloud prüft bei jedem eingehenden Aufruf automatisch, ob bereits eine Trace ID vorhanden ist, wenn nicht legt es eine neue Root Trace ID an. Für abgehende Aufrufe gibt es die aktuellen Trace Daten dem Aufruf mit. Bei abgeschlossenen Spans werden die Trace Daten asynchron zum Zipkin Server übertragen.
Integration in OpenText Documentum
Diese Tracing-Konzepte stellen eine ausgezeichnete Möglichkeit dar, um Informationen, welche durch unterschiedliche Services generiert wurden, zu sammeln. Diese Technologie bietet sich natürlich auch an um das Tracing für Documentum Services zu nutzen, also für D2 HTTP Aufrufe und Server Methoden. Auf diesem Wege erhält man einen deutlich besseren Überblick über den allgemeinen Prozessablauf – zusätzlich können allerdings auch effizient Engpässe identifiziert werden. Mit lediglich geringen Anpassungen, kann fast alles in eine solche Tracing Infrastruktur integriert werden.
Fazit
Wie bereits dargelegt, können Distributed Tracing Systems zur Überwachung und Fehlerbeseitigung von Microservice-basierten verteilten Systemen genutzt werden. Sie geben einen Gesamtüberblick und zeigen Details der jeweiligen hierarchischen Abhängigkeiten auf, wobei es irrelevant ist, wie viele Microservices involviert sind. Auf diesem Wege können Engpässe in einem spezifischen Microservice zielgerichtet identifiziert, verfolgt und beseitigt werden.
Der Tracing Server ist ressourcenschonend und kann in einem Docker Container betrieben werden. Trace Daten werden gesammelt und asynchron versendet, was potentielle Auswirkungen auf die Applikation minimiert. Das zugehörige Web UI ist außerdem sehr intuitiv in der Benutzerführung. Die Trace-Daten können im internen Speicher oder in einer externen Datenbank gespeichert werden.
Unabhängig von der eingesetzten Programmiersprache, lassen sich bestehende Services reibungslos um ein Remote Tracing zu erweitern.
Mir persönlich gefällt die Idee Tracing-Daten an einem Ort zentral zu konsolidieren, um so einen einfachen Überblick über verschachtelte Aufrufe und den Gesamtfluss des Programms zu erhalten. Außerdem bietet es mir – aus der Perspektive eines Entwicklers – die Möglichkeit weitere Informationen über die Trace-Daten mitzugeben, welche dann auf den Tracing Servern via Web UI überprüft werden können.
Lesen Sie ebenfalls:




0 Kommentare