
Dieser Blogbeitrag ist nur in englischer Sprache verfügbar. | This blog post is only available in English.
PERFORMANCE IS A KEY FACTOR IN MIGRATION PROJECTS
During the last decade spent in doing or supporting more than 200 migration projects, I have realized that in most of the cases the performance was one of the key indicators for a successful migration project. It is not solely important to get your data migrated correctly into the target system but also to meet the business deadlines that many times are quite tight. In the cloud era more and more ECM systems come with a web service API, therefore extracting or loading big loads of data becomes even more challenging than it is with on-premises systems.
MIGRATION-CENTER PERFORMANCE AND SCALABILITY
For small migration projects (1-2 million documents) there is nothing special you need to consider in terms of hardware and software requirements. All migration-center components can be run on the same machine by following the requirements described in the installation guide.
For medium and large migration projects, migration-center comes with a powerful, scalable and flexible architecture that allows different components to be deployed on multiple machines for reaching the maximum performance that is allowed by the environment (especially by the source and target systems which are in most cases the bottleneck).
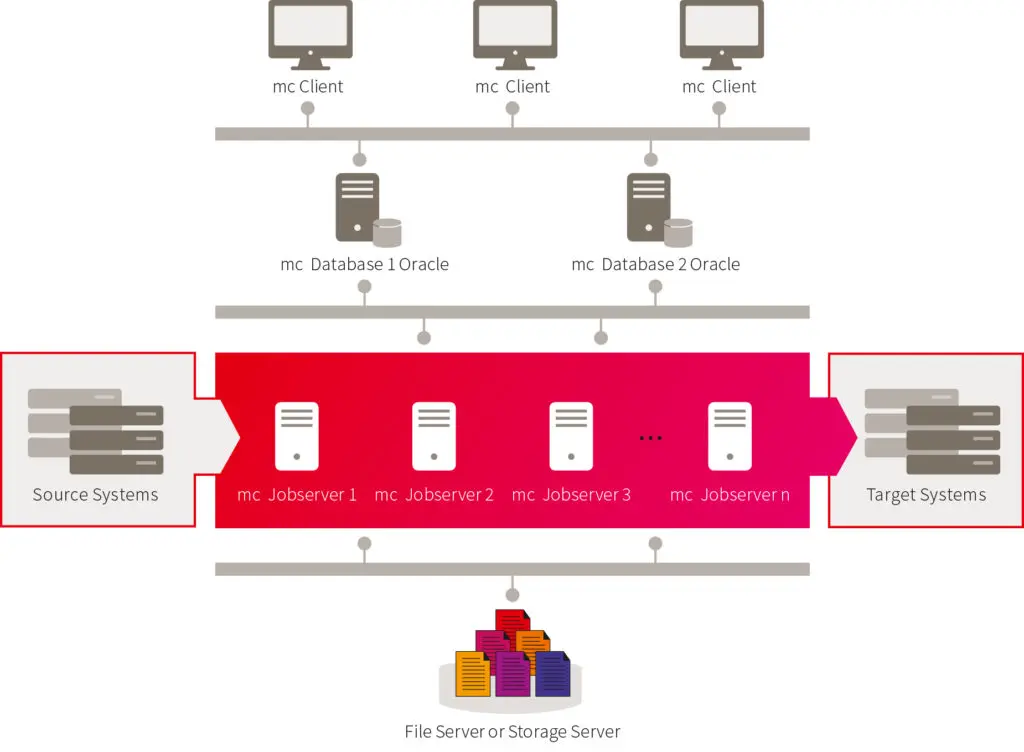
Architecture of migration-center
Every environment is different, not just in terms of the technical aspects or performance, but also in terms of people working on that system. For example end users, project managers or IT managers see and react differently to the migration and its requirements and implications. Therefore it is important to consider not just the technical factors but also the needs and possibilities of the people working with or managing the involved systems.
Over the time I could see a wide range of throughputs in different migration projects. I would like to share some examples here:
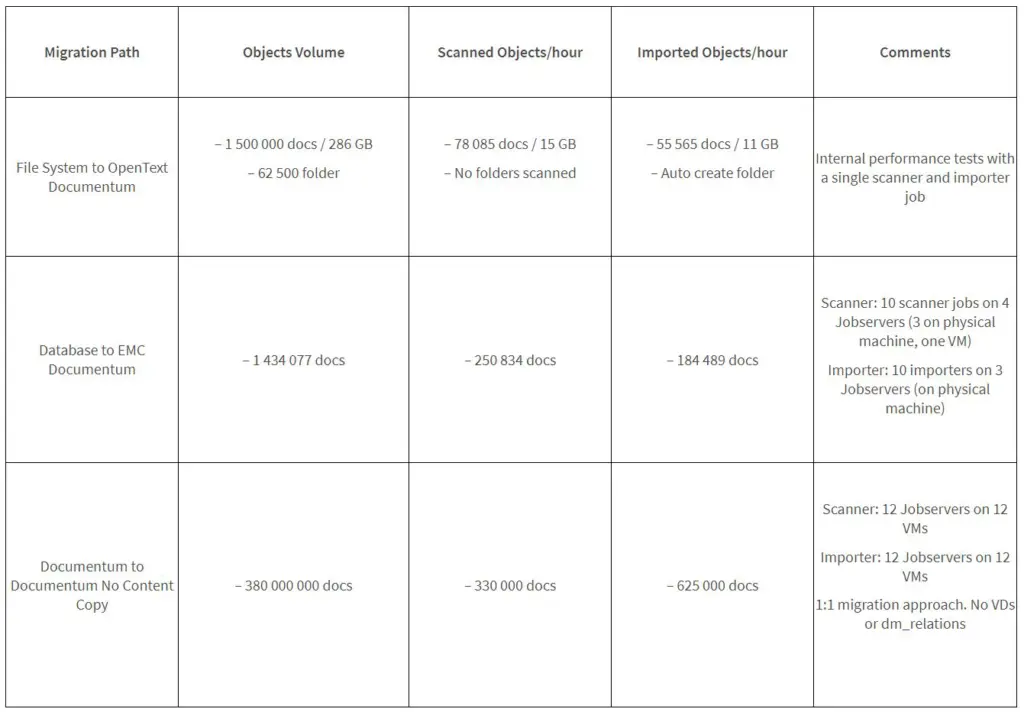
Table with examples
HOW CAN YOU IMPROVE THE PERFORMANCE?
JOBSERVER – EXPORTING AND LOADING DATA
During migration projects, most of the processing time is consumed by the Jobserver for extracting and loading the data from/to the ECM system. The performance of this process is very dependent on the performance capabilities of the source and target systems.
The most common ways to improve the performance of extracting and loading the data I can recommend, are the following:
- Make sure the Jobservers and the export location are deployed in the same network segment with the source and target repository. The performance of the communication between Jobserver and source/target repository is very important for the overall performance. The I/O rate for reading the actual content from the temporary export location is also a high factor here.
- Run multiple scanners and importers in parallel on multiple Jobservers deployed on several machines. Make sure you don’t scan the same objects on multiple parallel jobs. It would end up with having scanned those objects twice. Done properly, you can scale the performance up to the performance limit of the source and target system.
- How many jobs should you run in parallel for getting the best performance? There is no standard answer to this question. There are no hard limits but in most of the cases using two or more parallel jobs for extracting/loading the data is faster than processing the same amount of data with a single job. The limitation comes mostly from the throughput you can get from the source or target system. You can start with 2-4 jobs in parallel, and work your way up from there; i.e. if the performance is not satisfactory with 2-4 jobs, try launching 1-2 more jobs und a second Jobserver and observe whether throughput increases accordingly or not. This may not be the case, as several other factors lie between the Jobserver and the source/target system: network bandwidth, latency, storage system throughput, repository throughput, repository database performance, the migration-center database performance etc..
- Since extracting and loading performance is very dependent on the source and target system’s performance, you should make sure these systems perform well, especially when querying data. Obviously, loading data into the target system is the bottleneck overall. Make sure that the target system is setup to accept new objects in a performant way, e.g. with clustering, turning of index, rendition and other processing services.
If a web service is used for the import, consider to install several web service instances because that will drastically increase the performance.
CLIENT AND DATABASE
The performance of the client is highly dependent on the database performance thus it is recommended that the client and the database are running in the same segment of the network. They use the oracle client to communicate.
Nevertheless, I can suggest some hints that may result in a better performance when dealing with large amounts of data:
- Create smaller migsets, so you can parallelize the transformation, validation and even the import process. It is always better to have four migsets with 250.000 objects instead of having one migset with 1.000.000 objects.
- If possible, delete (clean-up) the older objects that were migrated in the past in order to reduce the number of source objects and migsets. Only do this if you do not need the data for audit reasons (history). Please also be aware that in doing so the delta migration approach for those old objects is not applicable any more.
- After scanning large amounts of data in a short period of time, make sure the Oracle statistics for the FMEMC schema (especially for the source_objects table) are collected so they reflect the number of objects in the table.
- If you need to migrate large amounts of data from different source systems you should consider using two or even more mc database instances or otherwise allocate enough resources in terms of memory and processor to a single Oracle instance. The different mc database cores are not related to each other though.
In past projects I’ve seen migrations dealing with 30.000.000 objects with just a single database but I have also seen more than 300.000.000 objects in a single Oracle instance. In this last example the Oracle instance was running on a dedicated server machine having 16 GB allocated to the SGA and 16 CPU cores.
CONCLUSION
When dealing with large migration projects, sizing the systems and planning the deployment of migration-center for the best performance is not an easy task. You need to run extensive tests (both functional and performance related) before planning the production phase. The more complex the migration requirements and the infrastructure are, the more important the test phase is. But not only is the migration-center setup important, also the corresponding platforms (source and target) must be prepared to reach a suitable throughput. This is often forgotten.




0 Kommentare