
In allen Bereichen der Informatik werden heutzutage Daten verarbeitet. Angesichts der stetig wachsenden Digitalisierung von Prozessen in Unternehmen, werden immer mehr Daten erhoben. Um die gesammelten Daten sinnvoll und effizient zu verarbeiten und Informationen daraus zu gewinnen, werden diese Daten modelliert. Das Ergebnis der Modellierung ist ein sogenanntes »Datenmodell«, welches Daten und ihre Beziehungen definiert und organisiert. Es hilft, Anforderungen zu verstehen, komplexe Informationen zu vereinfachen und dient als Grundlage für die Datenbankentwicklung.
Bei der Erstellung eines Datenmodells muss darauf geachtet werden, dass dieses auf das zugehörige Einsatzgebiet abgestimmt ist, um die Daten effizient zu verarbeiten und eine zielgerichtete Umsetzung von Anwendungen und Geschäftsprozessen zu ermöglichen. Es existieren viele verschiedene Möglichkeiten Datenmodelle zu erstellen, welche verschiedene Vor- und Nachteile mit sich bringen. In diesem Blogartikel möchte ich eine der wichtigsten historischen Techniken der Datenmodellierung vorstellen: Die dimensionale Modellierung nach Ralph Kimball.
Das dimensionale Modellieren findet besonders im Fachbereich der Business Intelligence/ Analytics Verwendung. Dort hat sich diese Technik, welche von Ralph Kimball entwickelt wurde, über Jahrzehnte hinweg zu einem der Modellierungsstandards der Business Intelligence gebildet. Dieses Modell legt keinen Fokus auf die Normalisierung, welche ein wesentlicher Bestandteil der Datenmodellierung von transaktionsbezogenen relationalen Datenbanken (OLTP) ist, sondern auf die analytische Verarbeitung großer Datenmengen (OLAP).
Was ist eigentlich ein dimensionales Datenmodell?
Beim einem dimensionalen Datenmodell werden die Daten nach dem Stern-Schema (Star-Schema) angeordnet. Das Datenmodell trägt den Namen, da die Anordnung der logischen Verknüpfungen der Datenmodell-Tabellen visuell der Form eines Sterns ähnelt. Das Stern-Schema gruppiert seine Daten bzw. Tabellen in zwei Arten: Fakten und Dimensionen. Es existieren eine Fakten- und beliebig viele Dimensionstabellen. Dabei bildet die Faktentabelle das Zentrum und die Dimensionstabellen die Zacken vom Stern. Aber was sind Fakten und Dimensionen?
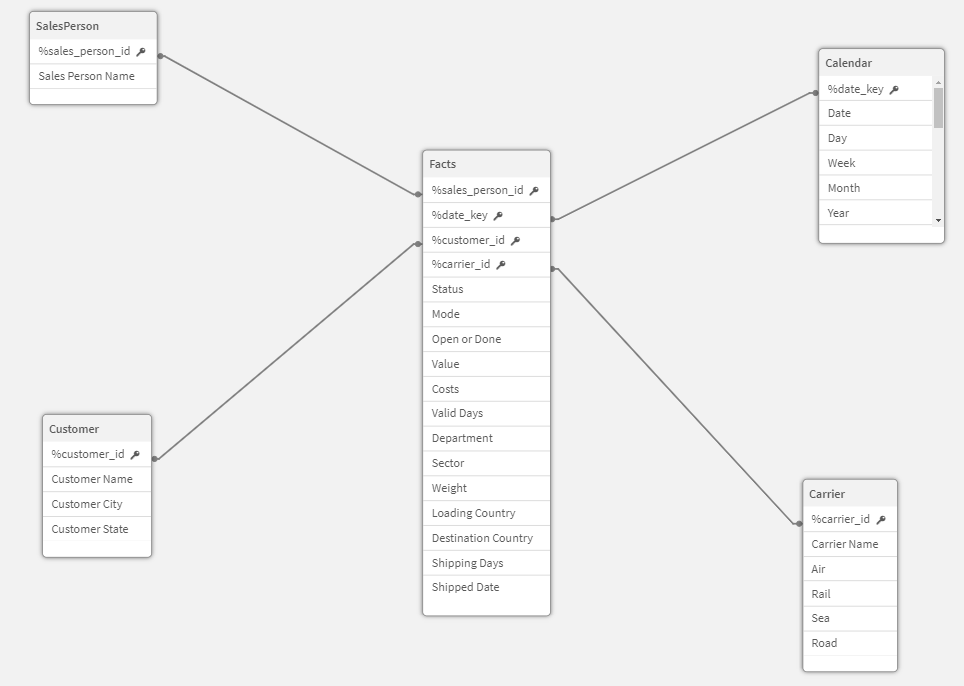
Fakten
Die Fakten sind nicht nur in der visuellen Anordnung der zentrale Punkt des Datenmodells, sondern stellt auch den Mittelpunkt der Analyse dar. Die Faktentabelle besteht größtenteils aus numerischen Kennzahlen oder Metriken, welche die Daten auf fein-granularer Ebene repräsentieren. Die Werte in einer Faktentabelle sind in der Regel Additive, d. h. sie werden summiert oder aggregiert, damit sie Informationen und Erkenntnisse liefern. Beispiele für Fakten sind die Anzahl an Webseitenbesucher, der Umsatz in einem definierten Zeitraum oder die Anzahl der verkauften Einheiten jedes Produkts in allen Transaktionen. Nach Kimball existieren verschiedene Arten von Faktentabellen. Zudem enthalten Faktentabellen Schlüsselfelder, welche die Beziehungen zu den Dimensionen darstellen.
Dimensionen
Im dimensionalen Datenmodell werden spezielle Dimensionen erstellt, um eine möglichst detailreiche Analyse zu ermöglichen. Diese Dimensionen erlauben eine fokussierte Betrachtung der Fakten bzw. Kennzahlen und stellen alle beschreibenden Attribute zu den Fakten bereit. Dabei werden die Informationen in den Dimensionen »distinct«, also einzigartig, gespeichert. Die Fakten selbst verweisen lediglich über einen Schlüsselwert, der auch in der entsprechenden Dimensionstabelle als Fremdschlüssel abgelegt ist, auf eine Dimension. Dadurch entsteht eine effiziente und effektive Verknüpfung der Daten, die eine präzise Analyse und tiefere Einblicke in das Geschäftsgeschehen ermöglicht.
Warum sollte das Stern-Schema genutzt werden?
Das Stern-Schema wird verwendet, weil es eine standardisierte, bewährte Methode bietet, um Daten für Analysezwecke zu gestalten. Die Hauptvorteile des Stern-Schemas sind:
- Hohe Flexibilität, Daten schnell und variabel Filtern zu können
- Leichte Erweiterbarkeit bei neuen Anforderungen oder Geschäftsprozessen
- Performance von JOINS in Datenbank Management Systemen
Weitere Vorteile ergeben sich durch eine mögliche Voraggregierung der Fakten, einfache logische Beziehungen zwischen Dimensionen und Fakten, sowie der unabhängigen Anpassung von Dimensionen und Fakten.
Kimball’s vier Schritte der dimensionalen Modellierung
Wollen Sie nun auch Ihre eigene Analyse mit Hilfe der dimensionalen Modellierung erstellen? Ich zeige Ihnen die vier Schritte zum dimensionalen Datenmodell. Dabei wird aufgrund der Performance, Flexibilität und Erweiterbarkeit ein Stern-Schema modelliert.
1. Geschäftsprozess identifizieren
Der erste Schritt ist recht einfach: Hier wird der Prozess, der analysiert werden soll, gewählt. Damit Sie entscheiden, welche Zahlen Sie im Prozess analysieren möchten, müssen Sie sich einen Überblick über alle zu diesem Prozess bestehenden Daten machen.
2. Granularität identifizieren
Nachdem Sie den ersten Schritt erfolgreich abgeschlossen haben, müssen Sie nun die Granularität der Analyse bestimmen. Die Granularität beschreibt den Detailgrad einer einzelnen Zeile der Faktentabelle. In einer Sales Analyse, die die am besten verkauften Produkte pro Tag analysieren soll, ist die Granularität z. B. »Produkt pro Tag«. Allgemein gilt die Annahme, dass die Analyse desto detailreicher ist, je höher die Granularität sei. Beachten Sie jedoch, dass hoch granulare Analysen von großen Datenmengen mit viel Speicher und Rechenaufwand einhergehen.
3. Dimensionen identifizieren
Wählen Sie anschließend die Dimensionen, welche die Fakten beschreibend unterstützen. Die Entscheidung ist in der Regel einfach, wenn Sie zuvor die passende Granularität gewählt haben. Im Beispiel der Sales Analyse ist die Dimension die Information des einzelnen Produkts, z. B. das Gewicht, der Hersteller oder der Einzelpreis.
4. Fakten identifizieren
Im letzten Schritt wählen Sie die Fakten der Analyse aus. Die Fakten sind die numerischen Kennzahlen, die den definierten Geschäftsprozess (Schritt 1) beschreiben. Dabei müssen Sie beachten, dass die definierte Granularität (Schritt 2), wie z. B. der Umsatz oder Gewinn im Beispiel der Sales Analyse, eingehalten wird.
Durch die Umsetzung dieser vier Schritte erhalten Sie ein dimensionales Datenmodell, das Ihnen ermöglicht, Ihre eigene Analyse durchzuführen. Es bietet eine solide Grundlage für die Strukturierung und Organisation Ihrer Daten, um wertvolle Erkenntnisse zu gewinnen und fundierte Entscheidungen zu treffen.
Dimensionales Modellieren in der Praxis
Das folgende Anwendungsbeispiel stellt Ihnen abschließend die Schritte auf dem Weg zu Ihrem dimensionalen Datenmodell anschaulich dar:
Schritt 1: Geschäftsanforderungen verstehen
Der Einzelhändler »SuperMart« möchte seine Verkaufsdaten analysieren. Die Geschäftsanforderung besteht darin, Einblicke in die Verkaufsleistung nach Produktkategorien, Filialen und Zeiträumen zu gewinnen.
Schritt 2: Granularität bestimmen
Um eine möglichst genaue Analyse zu erstellen, wird die kleinstmögliche Granularität im Anwendungsbeispiel das Produkt inklusive der Verkaufsdaten, gewählt.
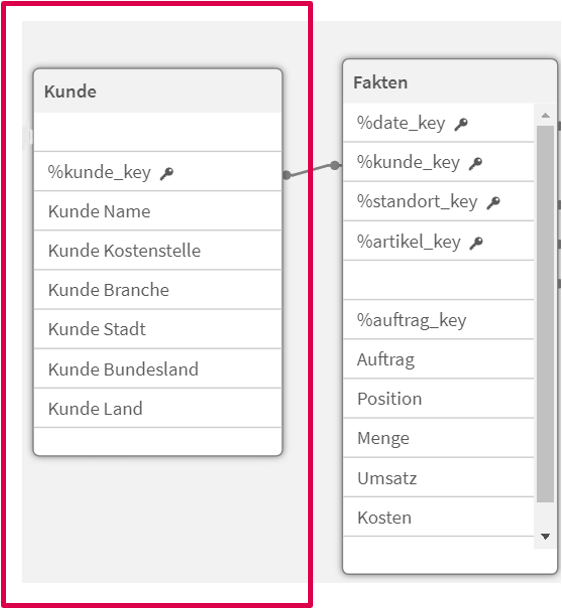
Schritt 3: Entwurf der Dimensionen
In diesem Schritt werden die relevanten Dimensionen identifiziert. Basierend auf den Geschäftsanforderungen werden die folgenden Dimensionen definiert:
- Produkt: Mit Attributen wie Produktname, Kategorie und Lieferant
- Filiale: Mit Attributen wie Filialname, Stadt und Region
- Zeit: Mit Attributen wie Jahr, Monat, Tag und Quartal
Schritt 4: Entwurf des Faktentabellenschemas
Die Faktentabelle wird entworfen, um die numerischen Messwerte zu erhalten, die analysiert werden sollen. Im Beispiel kann die Faktentabelle »Verkaufsfakten« folgende Messwerte enthalten:
- Verkaufsmenge
- Verkaufsumsatz
- Verkaufskosten
Die Faktentabelle wird mit den Dimensionstabellen (Produkt, Filiale, Zeit) durch Fremdschlüsselbeziehungen verknüpft.
Zuletzt wird das Datenmodell noch einmal überprüft und verfeinert. Dabei stellen wir sicher, dass die Hierarchien und Attribute in den Dimensionstabellen korrekt strukturiert sind und dass die Beziehungen zwischen den Tabellen konsistent sind.
Fazit
Das dimensionale Modellieren von Daten nach dem Konzept von Kimball ist ein bewährter Ansatz, welcher vor allem in der Branche »Business Intelligence & Analytics« verwendet wird und Unternehmen dabei unterstützen soll, wertvolle Erkenntnisse aus ihren Daten zu gewinnen und datengesteuerte Geschäftsentscheidungen zu treffen. Insgesamt wird das dimensionale Modellieren nach Kimball jedoch in Situationen verwendet, in denen es darum geht:
- Daten zu organisieren
- Daten zu analysieren
- Daten für die Entscheidungsfindung und Berichterstattung zugänglich zu machen.
Besuchen Sie unsere Webseite für weitere Einblicke zum Thema:




0 Kommentare